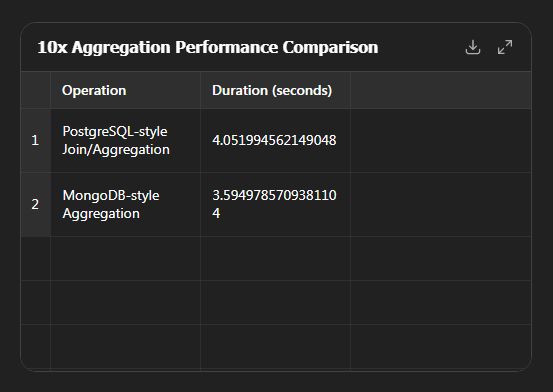
80% speed gain via Pre-Aggregated subsets vs MongoDB (which gains on bloat)
On PostgreSQL
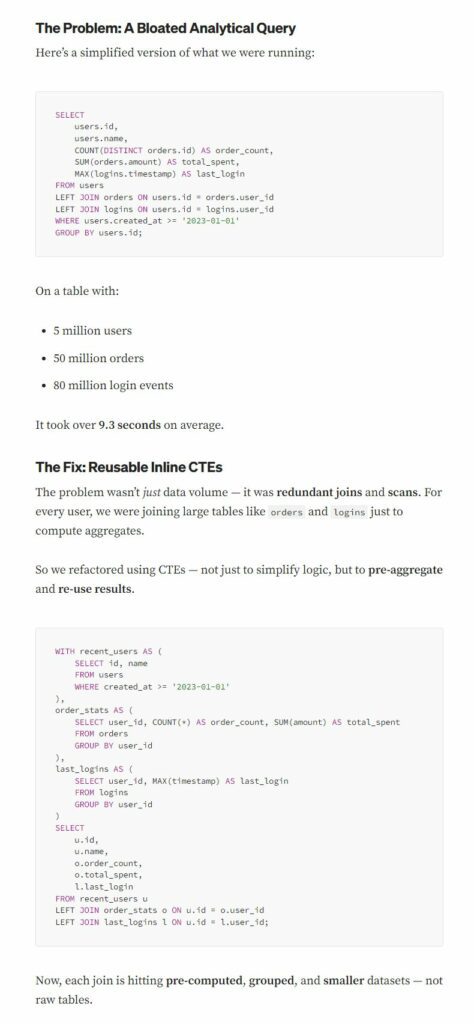

Compare against MongoDB
To precisely compare real-world speed between PostgreSQL pre-aggregation using CTEs vs MongoDB aggregation pipelines — Below is a detailed side-by-side analysis —

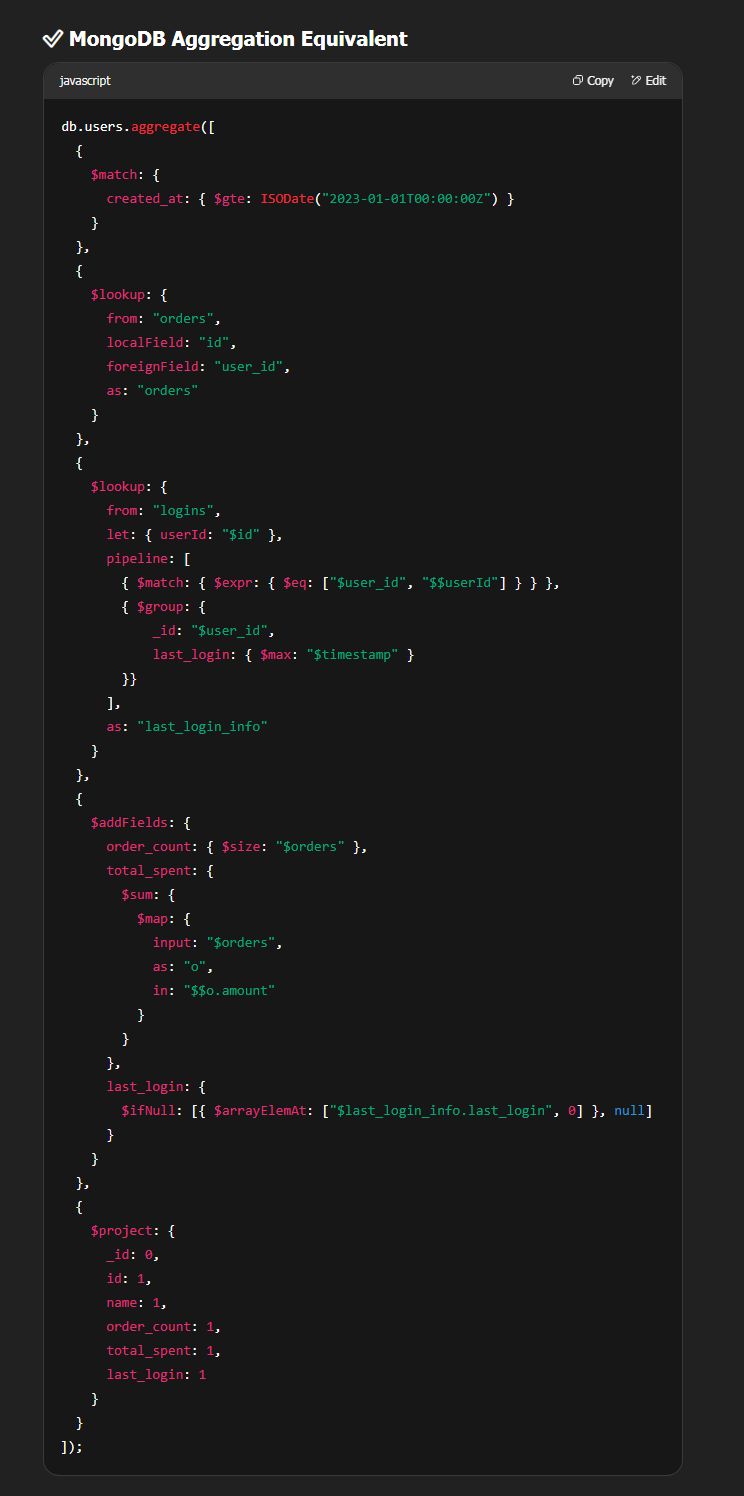

MongoDB 10% slower with smaller datasets —
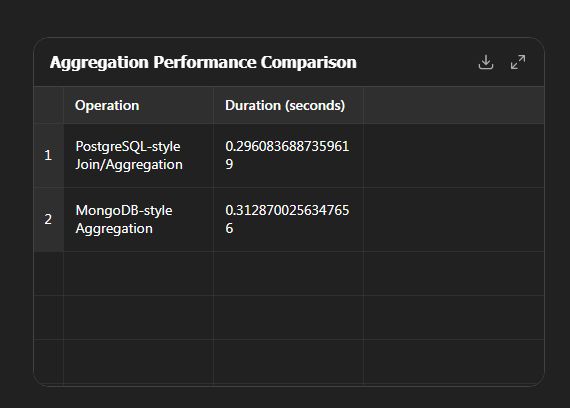
But MongoDB speed advantage increases with increasing datasets —
Here are the 10× scale results comparing PostgreSQL-style and MongoDB-style pre-aggregation using 1 million users, 10 million orders, and 5 million logins.